










구글, 메모리 덜 쓰는 신기술 공개
구글이 대규모 언어모델(LLM) 데이터를 기존보다 적은 자원으로 빠르게 처리할 수 있는 신개념 알고리즘 기술을 공개하자, 세계 주요 메모리 반도체 기업 주가가 줄줄이 하락
메모리 반도체 수요가 줄어들 수 있다는 우려가 투자 심리에 영향을 미친 것
삼성전자와 SK하이닉스의 시가총액 비중이 높은 코스피는 26일 3% 이상 하락하며 5,500 밑으로 떨어졌음
업계에선 이 기술이 적용되려면 오랜 시간이 필요하고 인공지능(AI)이 빠르게 발전하고 있는 만큼 메모리 반도체 수요 위축을 섣불리 예단하기는 어렵다고 봄
코스피는 이날 전 거래일 대비 3.22%(181.75포인트) 하락한 5,460.46에 거래를 마쳤음
외국인이 3조980억 원어치를 순매도하며 지수 하락을 주도
코스닥지수는 전 거래일 대비 1.98%(22.91포인트) 하락한 1,136.64에 마감
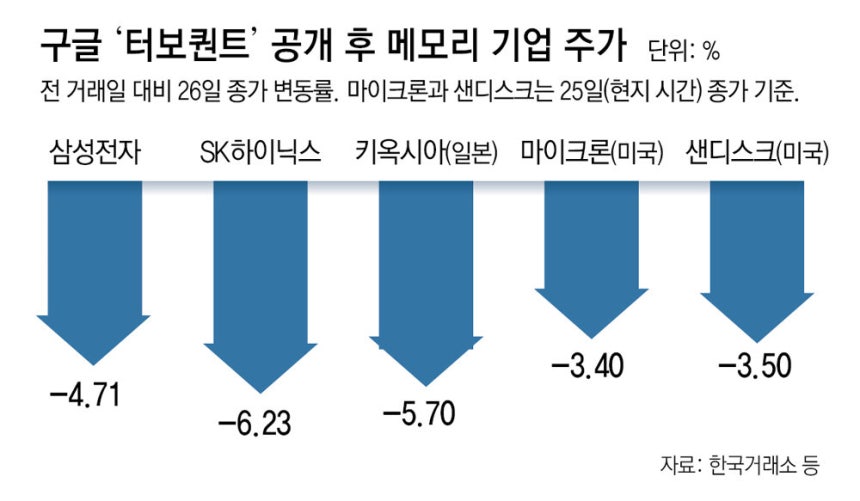
이날 코스피에선 전체 시총의 40.76%를 차지하는 ‘반도체 투톱’ 삼성전자(우선주 포함)와 SK하이닉스 하락 폭이 컸음. 삼성전자는 4.71% 떨어졌고, SK하이닉스는 6.23% 내렸음
삼성전자와 SK하이닉스의 주가가 크게 떨어진 것은 미국 구글이 공개한 새 알고리즘 기술 ‘터보퀀트’의 영향
구글리서치가 25일(현지 시간) 발표한 터보퀀트는 AI 효율성을 높여주는 기술

일반적으로 AI 모델은 복잡한 정보를 처리하기 위해 엄청난 양의 메모리(기억 장치)를 사용해야 함
반면 구글리서치 연구 결과에 따르면 터보퀀트를 쓰면 필요한 메모리 양이 기존보다 6분의 1로 줄어듬. 처리 속도는 엔비디아의 대표적인 그래픽처리장치(GPU) ‘H100’보다 최대 8배 빠른 것으로 나타났음. 데이터가 거의 손실되지 않게 압축해 처리하는 기술을 적용한 덕분
터보퀀트 같은 알고리즘 기술이 적용되면 메모리 반도체 수요가 줄어들 수 있다는 우려에 미국 뉴욕 증시가 먼저 반응
25일(현지 시간) 세계 메모리 반도체 3위 기업 마이크론 주가는 전 거래일 대비 3.4% 하락. 샌디스크(-3.5%)와 웨스턴디지털(-1.63%) 등 다른 메모리 업체 주가도 하락. 일본 메모리 반도체 업체 키옥시아 주가도 26일 전 거래일 대비 5.7% 내렸음
미국 정보기술(IT) 전문매체 테크크런치는 “터보퀀트를 통해 AI 모델이 기존보다 효율성을 높이고 메모리 수요를 줄이는 구조를 만들어 낼 가능성이 있다”고 짚었음
국내 증권업계에선 터보퀀트 연구 결과 공개에 따른 삼성전자와 SK하이닉스 등의 주가 하락세가 지나치다는 분석이 나옴
구글이 아직 연구 논문을 통한 결과를 공개한 것일 뿐 실제 상용화까지는 오랜 시간이 걸릴 수 있기 때문
김일혁 KB증권 연구원은 “데이터 처리 효율이 높아지면, 기업은 새로운 AI 기기 및 에이전트 개발에 더 투자할 것이고 다시 메모리 반도체 수요는 늘어날 수밖에 없다”고 분석
구글 터브퀀트발 반도체 쇼크
자료 : 서울경제신문
구글 리서치가 인공지능(AI) 구동에 필요한 메모리 사용량을 획기적으로 줄이는 ‘터보퀀트(TurboQuant)’를 공개하자 삼성전자(005930)·SK하이닉스(000660)·마이크론 등 메모리반도체 기업의 주가가 일제히 폭락
증설 속도 한계에 따른 상반기 실적 ‘피크아웃(정점 통과)’론이 지속되는 와중에 기술 발달로 메모리 수요 자체가 꺾일 수 있다는 우려가 더해진 결과
다만 시장에서는 터보퀀트의 파급력이 마케팅적으로 과장된 측면이 있고 본격적으로 도입된다 해도 AI 메모리 공급절벽의 ‘해갈’ 수준을 넘기 힘든 만큼 과도한 공포를 경계해야 한다는 분석도 이어짐
오히려 AI 대중화를 앞당김으로써 장기적으로는 메모리 수요를 폭증시킬 것이라는 반론이 나옴
터보퀀트는 AI가 문맥을 기억하는 데 사용하는 데이터를 3비트(FP3)로 무손실 압축하는 알고리즘
기존 데이터 압축 기술들이 4비트(FP4) 이하에서는 정확도가 크게 떨어지고 보정을 위해 사전 학습과 튜닝이 필요했던 점을 보완
구글은 터보퀀트 적용 시 AI 메모리 사용량을 최대 6배 줄이고 엔비디아 H100 그래픽처리장치(GPU)에서 연산 속도를 최대 8배까지 끌어올릴 수 있다고 밝혔음
소프트웨어 최적화로 고대역폭메모리(HBM) 등 메모리 의존도를 낮추게 돼 수요 둔화로 이어질 수 있다는 우려에 불을 지핀 것
구글은 다음 달 브라질에서 열리는 AI 학회 ICLR 2026에서 구체적인 터보퀀트 연구 성과를 공개할 계획
앞서 반도체 업종에서는 19일 마이크론의 실적 발표 이후 피크아웃 논란이 불거져왔음. 절대적인 이익 규모는 커지고 있으나 실적 ‘상승 기울기’가 정점을 지나고 있다는 불안감
전날 대신증권은 삼성전자·SK하이닉스에 대해 1분기 실적 발표에서 반도체 실적의 피크아웃 우려를 완화하는 것이 향후 주가 향방의 핵심이라고 짚었음
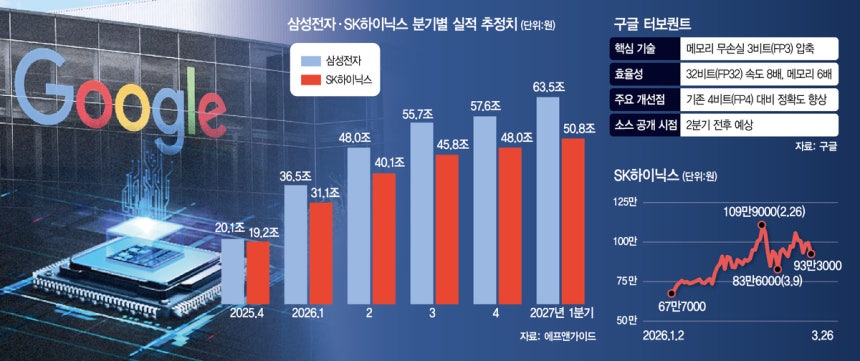
금융 정보 업체 에프앤가이드에 따르면 올 1분기 삼성전자의 영업이익은 36조 4768억 원으로 전 분기보다 81.7% 늘어날 것으로 전망됨
올해 영업이익이 2분기(47조 9531억 원·31.5%)부터 4분기(57조 5732억 원·3.3%)까지 꾸준히 개선되겠으나 이익 증가율은 갈수록 줄어든다는 관측
SK하이닉스 역시 올 1분기 31조 1282억 원(62.4%)에서 4분기 48조483억 원(4.9%)으로 유사한 흐름을 보일 것으로 전망됨
폭발적인 수요를 뒷받침할 설비 증설 속도의 한계가 발목을 잡는 것임
삼성전자의 평택 P4·P5 라인과 SK하이닉스의 용인 반도체 클러스터 등은 2027년 말에야 본격 가동이 가능해 그 전까지는 메모리 물량 확대가 힘든 구조임
반도체 업계 관계자는 “메모리 업체들이 빅테크와 구속력 높은 장기 물량 계약을 맺고 있어 가격 방어력은 강하지만 이는 추가적인 단가 인상이 힘들다는 뜻이기도 하다”며 “유의미한 공급 증가 없이는 지금과 같은 폭발적인 성장세가 이어지기 힘들다”고 말했음
터보퀀트 쇼크와 피크아웃 공포가 과장돼 ‘찻잔 속 태풍’에 그칠 것이라는 반론도 만만찮음
구글이 내세운 ‘메모리 6배, 속도 8배 향상’은 압축을 전혀 거치지 않은 32비트(FP32)를 기준으로 한 이론상 최댓값임. AI 추론의 70~80%는 이미 8비트(FP8)로 이뤄지고 있고 온디바이스(에지)는 4비트가 주류다. 실제 터보퀀트 적용으로 기대되는 메모리 감소량은 최대 2.6배 수준에 그치는 셈임
반도체 업계의 한 관계자는 “아직 연구 논문 수준으로 실제 적용까지는 시차가 소요될 것으로 전망된다”며 “모든 클라우드 업체가 이 기술을 사용할 수 있다는 보장도 없다”고 했음
메모리 압축 기술의 등장이 AI 모델 고성능화를 불러올 뿐 반도체 수요를 꺾지는 않을 것이라는 관측 또한 있음
모건스탠리는 “터보퀀트로 인해 AI 운영 비용이 6분의 1 수준으로 낮아지면 비용 부담으로 도입을 망설이던 기업들이 AI 생태계에 진입하게 될 것”이라며 “이는 전체 메모리 총수요를 줄이는 것이 아니라 오히려 AI 시장의 파이 자체를 키우는 촉매제가 될 것”이라고 진단
자원의 이용 효율이 높아지면 비용이 하락하게 되고 이는 결국 해당 자원의 전체 소비량을 폭발적으로 늘린다는 ‘제번스의 역설(Jevons Paradox)’임
지난해 초 중국발 ‘딥시크 쇼크’가 반도체 수요를 꺾지 못했다는 학습 효과 역시 남아 있음
메모리 기업 밸류에이션도 여전히 낮음. 현 국내 반도체 업종의 12개월 선행 주가수익률(PER)은 6.5배 수준에 불과. 이종욱 삼성증권 연구원은 “AI 업체들이 비용 경쟁이 아니라 성능 경쟁을 하는 한 비용 최적화는 반도체 수요에 영향을 미치지 않는다”며 “걱정해야 할 순간은 AI 업체들이 경쟁을 멈출 때”라고 강조
터보퀀트 기술의 정밀 분석
터보퀀트 기술의 수학적 기초와 아키텍처 분석
구글 리서치가 제안한 터보퀀트(TurboQuant)는 대규모 언어모델(LLM)의 추론(Inference) 단계에서 발생하는 핵심 병목 지점인 키-값 캐시(Key-Value Cache, KV Cache)를 타겟으로 설계된 혁신적인 벡터 양자화(Vector Quantization) 알고리즘
이 기술의 핵심은 기존의 양자화 방식이 가졌던 정보 손실과 연산 오버헤드라는 두 마리 토끼를 수학적 정교함을 통해 동시에 해결했다는 점에 있음
(자료 : TURBOQUANT: ONLINE VECTOR QUANTIZATION WITH NEAR-OPTIMAL DISTORTION RATE - OpenReview, https://openreview.net/pdf/6593f484501e295cdbe7efcbc46d7f20fc7e741f.pdf )
KV 캐시의 병목 현상과 메모리 세금(Memory Tax)의 실체
인공지능 모델이 긴 문맥을 이해하고 답변을 생성하기 위해서는 이전 대화의 맥락을 저장해야 하며, 이를 위해 매번 동일한 계산을 반복하지 않도록 Key와 Value 행렬을 메모리에 보관하는데 이것이 KV 캐시임
문맥 윈도우(Context Window)가 확장될수록 KV 캐시가 차지하는 메모리 용량은 모델 자체의 파라미터 크기를 상회하게 되며, 이는 GPU의 VRAM 부족과 추론 지연 시간(Latency) 증가의 결정적 원인이 됨
기존의 양자화 방식은 이를 해결하기 위해 부동 소수점 데이터를 낮은 비트의 정수로 변환했으나, 압축률을 높일수록 모델이 환각 현상을 보이거나 정확도가 떨어지는 한계가 있었음
또한, 압축 데이터를 복원하기 위해 각 블록마다 저장해야 하는 '정규화 상수'가 전체 용량의 상당 부분을 차지하는 '메모리 세금' 문제도 심각했음
( 자료 : Google TurboQuant Sparks Turmoil In Memory Market - Evrim Ağacı, https://evrimagaci.org/gpt/google-turboquant-sparks-turmoil-in-memory-market-535240
TurboQuant: Redefining AI efficiency with extreme compression - Google Research, https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
Google's new TurboQuant algorithm speeds up AI memory 8x, cutting costs by 50% or more, https://venturebeat.com/infrastructure/googles-new-turboquant-algorithm-speeds-up-ai-memory-8x-cutting-costs-by-50)
하드웨어 가속 최적화 및 런타임 효율성
터보퀀트는 단순히 이론적인 압축률에만 집중하지 않고, 실제 하드웨어 가속기에서의 실행 속도를 최적화하는 데 주안점을 두었음
엔비디아(NVIDIA) H100 GPU 환경에서 4비트 터보퀀트를 적용한 결과, 양자화되지 않은 32비트 키 값을 사용할 때보다 어텐션 로짓(Attention Logit) 계산 속도가 최대 8배 향상되는 결과가 관찰되었음
이는 메모리 사용량 절감이 단순히 저장 공간의 절약을 넘어, 실제 서비스의 응답 속도와 서버의 처리량(Throughput)을 비약적으로 증가시킨다는 것을 의미
터보퀀트 성능 벤치마크 및 비교 분석
구글 리서치는 터보퀀트의 우수성을 입증하기 위해 기존의 표준적인 양자화 기법인 KIVI 및 제품 양자화(Product Quantization, PQ)와의 비교 테스트를 수행
특히 롱벤치(LongBench)와 '바늘 찾기(Needle In A Haystack)' 테스트를 통해 긴 문맥 처리 능력을 철저히 검증
주요 벤치마크 데이터 요약
실험 결과, 터보퀀트는 젬마(Gemma)와 미스트랄(Mistral), 라마(Llama) 등 대표적인 오픈소스 모델 군에서 모델의 로직이나 추론 품질을 해치지 않으면서도 압축률과 속도 면에서 기존 기술을 압도했음
특히 벡터 검색(Vector Search) 성능에서도 기존의 하이엔드 방식인 라비큐(RabbiQ)나 제품 양자화보다 높은 재현율(Recall)을 기록하며 정보 검색 시스템에서의 활용 가능성도 입증했음
(자료 : Google's TurboQuant reduces AI LLM cache memory capacity requirements by at least six times — up to 8x performance boost on Nvidia H100 GPUs, compresses KV caches to 3 bits with no accuracy loss | Tom's Hardware, https://www.tomshardware.com/tech-industry/artificial-intelligence/googles-turboquant-compresses-llm-kv-caches-to-3-bits-with-no-accuracy-loss)
터보퀀트발 반도체 쇼크의 시장진단
‘터보퀀트 쇼크’의 본질은 AI 반도체 시장의 수요 구조에 대한 시장 참여자들의 ‘내러티브(Narrative) 붕괴’에 있음
그동안 시장은 AI 모델의 파라미터가 기하급수적으로 늘어나고 문맥 길이가 길어짐에 따라, 이를 담아낼 그릇인 HBM과 DRAM의 수요 역시 무한히 팽창할 것으로 믿어 의심치 않았음
하지만 구글은 소프트웨어의 혁신만으로 그 '그릇'의 크기를 6분의 1로 줄여도 충분하다는 사실을 보여줌으로써, 메모리 제조사들의 장밋빛 미래에 찬물을 끼얹었음
국내외 증시의 연쇄 급락과 투자 심리 위축
3월 26일 국내 증시에서 삼성전자는 전일 대비 4.71% 하락한 18만 100원에, SK하이닉스는 6.23% 급락한 93만 3,000원에 거래를 마쳤음
특히 외국인 투자자들은 삼성전자에서만 2조 원이 넘는 순매도를 기록하며 지수 하락을 주도
이러한 폭락세는 전날 뉴욕 증시에서 마이크론(-3.40%), 샌디스크(-3.50%), 웨스턴 디지털(-1.63%) 등이 동반 하락한 것의 연장선상에 있음
시장은 공급 과잉 우려와 실적 정점 통과(Peak-out) 논란이 제기되는 민감한 시기에 터보퀀트라는 메가톤급 변수를 만났고, 이는 즉각적인 차익 실현과 패닉 셀링(Panic Selling)으로 이어졌음
반도체 밸류체인 전반으로의 충격 확산
이번 쇼크는 소수의 완성차 칩 제조사에만 국한되지 않았음. 일본의 낸드플래시 거두인 키오시아(Kioxia) 역시 6% 이상 급락했으며, 중국의 기가디바이스(GigaDevice)와 몽타주 테크놀로지(Montage Technology)의 주가도 각각 5.89%, 3.53% 하락하며 아시아 전역의 반도체 밸류체인이 흔들리는 모습을 보였음
메모리 수요 둔화는 반도체 전공정 및 후공정 장비 업체, 소재 기업들의 실적 전망에도 부정적인 영향을 미칠 수 있다는 우려를 낳았음
제본스의 역설(Jevons Paradox): 효율성이 수요를 창출하는 논리
하지만 금융권과 학계의 일부 전문가들은 이번 시장의 반응이 과도한 ‘헤드라인 쇼크’에 불과하다고 지적하며 제본스의 역설을 인용
19세기 경제학자 윌리엄 스탠리 제본스가 관찰했듯이, 석탄 이용의 효율성이 개선되자 오히려 석탄 소비량이 폭증했던 것처럼, AI 구동 비용의 하락은 AI 서비스의 대중화와 응용 분야의 확대를 불러와 장기적으로는 메모리 수요를 더욱 폭증시킬 것이라는 논리
모건스탠리는 이번 하락을 구조적 하락의 시작이 아닌 ‘밸류에이션 리셋’의 기회로 규정하며 오히려 매수 기회로 삼을 것을 권고
기술적 관점에서 본 반도체 수요의 질적 변화
터보퀀트가 메모리 수요의 ‘양적’ 성장을 저해할 것이라는 공포에도 불구하고, 하드웨어의 물리적 사양은 여전히 AI 성능의 절대적 기준점으로 남을 가능성이 높음
소프트웨어는 레시피(Recipe)일 뿐이며, 메모리 칩은 여전히 그 요리를 담는 핵심 용기(Vessel)이기 때문
(자료 : MU, WDC, SNDK fall: Why Google's TurboQuant is rattling memory stocks By Investing.com, https://www.investing.com/news/stock-market-news/mu-wdc-sndk-fall-why-googles-turboquant-is-rattling-memory-stocks-4580176)
HBM3e에서 HBM4로의 로드맵 가속화
터보퀀트가 구현하는 8배의 연산 속도 향상을 온전히 누리기 위해서는 데이터를 연산 장치로 빠르게 전달할 수 있는 대역폭의 확보가 더욱 절실해짐
구글의 자사 ASIC인 TPU v5p나 엔비디아의 블랙웰(Blackwell) 아키텍처는 터보퀀트와 같은 고효율 알고리즘을 소화하기 위해 더 높은 대역폭을 지원하는 HBM3e와 차세대 HBM4 채택을 서두르고 있음
SK하이닉스와 삼성전자가 주도하는 HBM 로드맵은 단순히 용량을 늘리는 것이 아니라, 알고리즘 처리 효율을 극대화할 수 있는 커스텀 HBM 시장으로 빠르게 재편될 것으로 보임
온디바이스 AI(On-device AI) 시장의 개막
터보퀀트가 가져올 가장 가시적인 변화는 스마트폰, 노트북, 자율주행차 등 엣지 기기에서의 AI 구동임
기존에는 메모리 용량 부족으로 인해 클라우드 연결 없이는 불가능했던 거대 모델의 추론이 터보퀀트를 통해 로컬 기기 내에서 가능해지기 때문
이는 기존의 서버 중심 메모리 수요 외에, 수십억 대의 모바일 기기가 고성능 LPDDR 메모리를 탑재해야 하는 거대한 신규 시장을 창출
가트너(Gartner) 등 시장조사기관은 2026년 이후 스마트폰과 PC 당 탑재되는 메모리 용량이 AI 에이전트 기능을 위해 다시 한번 가파르게 상승할 것으로 내다보고 있음
하드웨어 사양의 '상향 평준화'와 무한 확장성
인공지능 개발자들은 효율적인 알고리즘이 나오면 비용을 절감하는 데 그치지 않고, 남는 자원을 활용해 더 크고 똑똑한 모델을 만들려는 경향이 있음
구글이 제미나이 1.5 프로에서 1,000만 토큰을 테스트하고도 비용 때문에 출시하지 못했던 사례를 보면, 터보퀀트 같은 기술은 오히려 인간이 더 방대한 지능을 요구하도록 부추기는 촉매제가 됨
즉, 단위당 메모리 소요량은 줄어들지 몰라도, 사용자가 원하는 AI의 지능 수준이 높아짐에 따라 전체 시스템이 요구하는 절대적인 메모리 사양은 여전히 '상향 평준화'될 수밖에 없음
하드웨어 아키텍처의 혁신
터보퀀트와 같은 고도화된 소프트웨어 기술은 기존의 범용 컴퓨팅 하드웨어에 새로운 도전 과제를 제시하며, 아키텍처 차원의 혁신을 강제하고 있음
연산 유닛의 세분화와 효율성 경쟁
현재 AI 가속기 시장은 엔비디아의 범용 GPU와 구글의 TPU, 테슬라의 DOJO 같은 전용 ASIC, 그리고 저전력 추론을 위한 NPU로 세분화되고 있음
터보퀀트는 특히 '행렬 곱셈'과 '벡터 처리'에 특화된 구조를 가지고 있어, 이러한 연산을 가장 적은 전력으로 수행할 수 있는 전용 하드웨어에 대한 수요를 촉발
지능형 메모리(PIM)와 컴퓨팅 인 메모리(CIM)의 부상
전문가들은 미래의 인공지능 시스템이 '연산 중심'에서 '메모리 중심'으로 완전히 전환되어야 한다고 주장
삼성전자와 SK하이닉스가 개발 중인 PIM(Processing-In-Memory)은 메모리 내부에서 직접 연산을 수행함으로써 데이터 이동에 소요되는 에너지와 시간을 획기적으로 줄임
터보퀀트의 양자화 및 복원 과정을 메모리 칩 내부에서 수행할 수 있다면, 현재 구글이 주장하는 8배 속도 향상을 넘어선 천 배 이상의 효율 개선도 이론적으로 가능하다는 것이 'AI+HW 2035' 화이트페이퍼의 전망임
하드웨어 가속기 시장 비교 분석
국내 반도체 기업의 대응 전략
구글의 터보퀀트 기술이 던진 화두는 명확
이제 메모리 반도체 기업은 단순한 '제조사'에 머물지 말고, 소프트웨어와 하드웨어를 아우르는 '솔루션 프로바이더'로 거듭나야 한다는 것임
하드웨어-소프트웨어 공동 설계(Co-design) 역량 강화
이제 칩 설계 단계부터 구글, 메타, OpenAI와 같은 빅테크 기업들의 알고리즘 로드맵을 깊숙이 반영해야 함
삼성전자가 AMD와 체결한 차세대 AI 메모리 협력 MOU나 SK하이닉스의 엔비디아 밀착 행보는 이러한 흐름의 시작임
메모리 제조사가 소프트웨어 최적화 툴킷을 직접 제공하거나, 터보퀀트와 같은 압축 알고리즘을 하드웨어 수준에서 가속하는 전용 컨트롤러를 칩에 내장하는 식의 혁신이 필요
커스텀 HBM 및 차세대 인터페이스(CXL) 주도권 확보
터보퀀트로 인해 메모리 용량에 대한 압박은 다소 완화될 수 있으나, 시스템 유연성에 대한 요구는 더욱 커질 것임
고객사별로 상이한 연산 요구 사항에 맞춰 베이스 다이(Base Die)에 로직 기능을 추가한 '커스텀 HBM' 시장은 한국 기업들이 압도적인 제조 경쟁력을 바탕으로 선점해야 할 고부가가치 영역임
또한, 메모리 풀링을 통해 자원을 효율적으로 분배하는 CXL(Compute Express Link) 생태계를 확장하여, 소프트웨어 효율화가 가져올 시스템 아키텍처의 변화에 능동적으로 대응해야 함
온디바이스 AI용 프리미엄 메모리 포트폴리오 확대
서버용 HBM에 쏠린 시선을 모바일과 PC용 프리미엄 DRAM으로 넓혀야 함
터보퀀트를 통해 열릴 온디바이스 AI 시장은 수십억 대의 잠재적 수요를 가진 거대 시장임
기존 LPDDR보다 성능이 뛰어나면서도 전력 효율이 극대화된 LPDDR6 및 압축 데이터 처리에 특화된 전용 메모리 솔루션을 조기에 양산하여 스마트폰 업체들을 고객사로 포섭해야 함
기술 가치에 대한 적극적인 시장 소통(IR) 전략
이번 쇼크는 기술적 실체에 대한 오해와 시장의 과도한 공포가 결합된 결과
기업들은 알고리즘의 발전이 오히려 하드웨어 교체 수요를 자극하고, AI 시장의 파이를 키우는 긍정적인 요인임을 논리적으로 증명해야 함
또한, 자사의 기술이 단순히 용량 경쟁을 넘어 알고리즘 효율화를 어떻게 지원하고 있는지 구체적인 로드맵을 제시함으로써 투자자들의 신뢰를 회복해야 함
<시사점>
구글의 Google Research가 내놓은 ‘터보퀀트(TurboQuant)’는 단순한 알고리즘 개선이 아닙니다. 그것은 지난 수년간 반도체 산업을 지탱해온 ‘메모리는 많을수록 좋다’는 공식을 뒤흔드는 기술적 도전장이자, 동시에 새로운 수요 창출의 출발점입니다. 국내외 증시가 즉각적으로 충격에 반응한 것은 이해할 만합니다. 그러나 시장의 공포가 곧 산업의 미래를 대변하는 것은 아닙니다.
이번 충격의 본질은 수요의 소멸이 아니라 ‘수요 구조의 재편’에 있습니다. 터보퀀트는 인공지능 추론 과정에서 핵심 병목이었던 KV 캐시를 정교한 벡터 양자화 방식으로 압축함으로써 메모리 사용량을 획기적으로 줄였습니다. 이로 인해 NVIDIA의 GPU 기반 시스템에서조차 기존 대비 수배 이상의 성능 향상이 가능해졌습니다. 시장은 이를 ‘메모리 덜 필요’라는 단선적 메시지로 받아들였지만, 실제로는 ‘같은 자원으로 더 많은 AI를 돌릴 수 있는 시대’가 열린 것입니다.
여기서 주목해야 할 것은 경제학의 고전적 통찰, 즉 제본스의 역설입니다. 효율성의 증가는 소비의 감소가 아니라 확장을 불러옵니다. AI 연산 비용이 낮아질수록 기업과 개인은 더 많은 AI 서비스를 사용하게 되고, 이는 결과적으로 전체적인 컴퓨팅 수요와 메모리 수요를 오히려 증폭시킵니다. 이번 사태를 ‘슈퍼사이클의 종말’로 해석하는 것은 섣부른 결론입니다.
특히 터보퀀트가 열어젖힌 가장 중요한 시장은 온디바이스 AI입니다. 그동안 대규모 언어모델은 클라우드 데이터센터에 의존할 수밖에 없었지만, 이제는 터보퀀트 기술로 스마트폰과 PC, 자동차 등 엣지 기기에서도 직접 구동이 가능해질 수 있게 되었습니다. 이는 단순한 기술 진보를 넘어 산업 구조 자체를 바꾸는 변화입니다. 수십억 대의 기기가 AI 기능을 상시 구동하기 위해 고성능 메모리를 탑재해야 하는 시대가 도래하는 것입니다. 결과적으로 서버용 HBM 중심이었던 수요 축은 모바일용 LPDDR, 차량용 메모리 등으로 급격히 확장될 가능성이 큽니다.
또 다른 변화는 ‘메모리의 질적 진화’입니다. 터보퀀트는 단순 저장 장치로서의 메모리가 아니라, 알고리즘과 결합된 ‘연산 친화적 메모리’를 요구합니다. 이는 삼성전자와 SK하이닉스가 강점을 가진 HBM과 PIM(Processing-In-Memory) 기술의 전략적 가치를 더욱 부각시키는 대목입니다. 앞으로의 경쟁은 용량이 아니라 ‘얼마나 효율적으로 AI 연산을 지원하느냐’로 이동할 것입니다.
결국 이번 터보퀀트 쇼크는 위기가 아니라 방향 전환의 신호입니다. 반도체 산업은 더 이상 물리적 확장만으로 성장할 수 없습니다. 소프트웨어와 하드웨어의 공동 설계, 맞춤형 메모리, 그리고 온디바이스 AI 생태계 대응이 새로운 경쟁력을 결정짓습니다. 시장이 공포에 휩싸일 때일수록 산업은 진화의 기회를 맞습니다.
지금 필요한 것은 과도한 비관이 아니라 냉정한 해석입니다. 터보퀀트는 메모리 수요를 줄이는 기술이 아니라, AI의 문턱을 낮춰 ‘더 많은 곳에서, 더 자주, 더 깊게’ 사용되도록 만드는 촉매입니다. 그 결과는 명확합니다. 반도체 수요는 사라지지 않으며, 오히려 더 넓고, 더 깊게 확장될 것입니다.
<관련 기사>
https://n.news.naver.com/article/newspaper/020/0003707423?date=20260327







